
有一說一,表情辨識到底還是個分類任務。
如果我說有一種演算法可以在不需要標籤的情況下自動幫我們分組,你相信嗎?
那就叫分群演算法(clustering)!
機器學習可分成三種:
分群演算法適用在第2、3種情況,
而今天最經典的分群演算法當屬k-means了!可能連高中生也聽過

所謂的pseudo-label是指我們在做半監督式學習時,
給予未標籤的資料一個偽標籤。(好饒舌)
假設我們有兩組訓練資料,但其中一組資料為unlabeled data
我們用labeled data那組去訓練一個機器學習模型(Model A)
(這裡的機器學習可以是監督也可以是非監督,但由於已經有label了,在此推薦用監督)
Model A已經學會將資料分類了,於是我們將Model A對unlabeled data進行預測分類即生成偽標籤。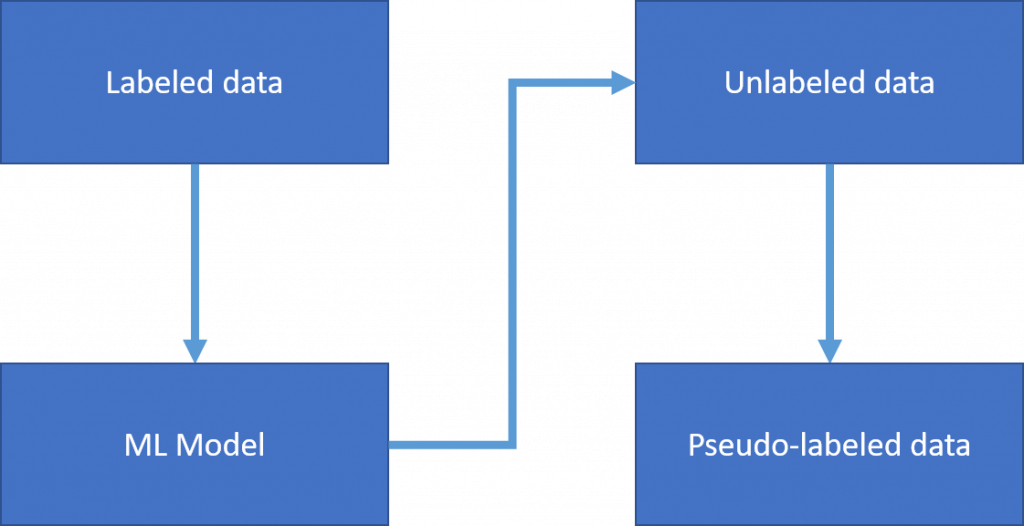
接下來我們合併labeled data和pseudo-labeled data,訓練出一個完整的機器學習模型(Model B)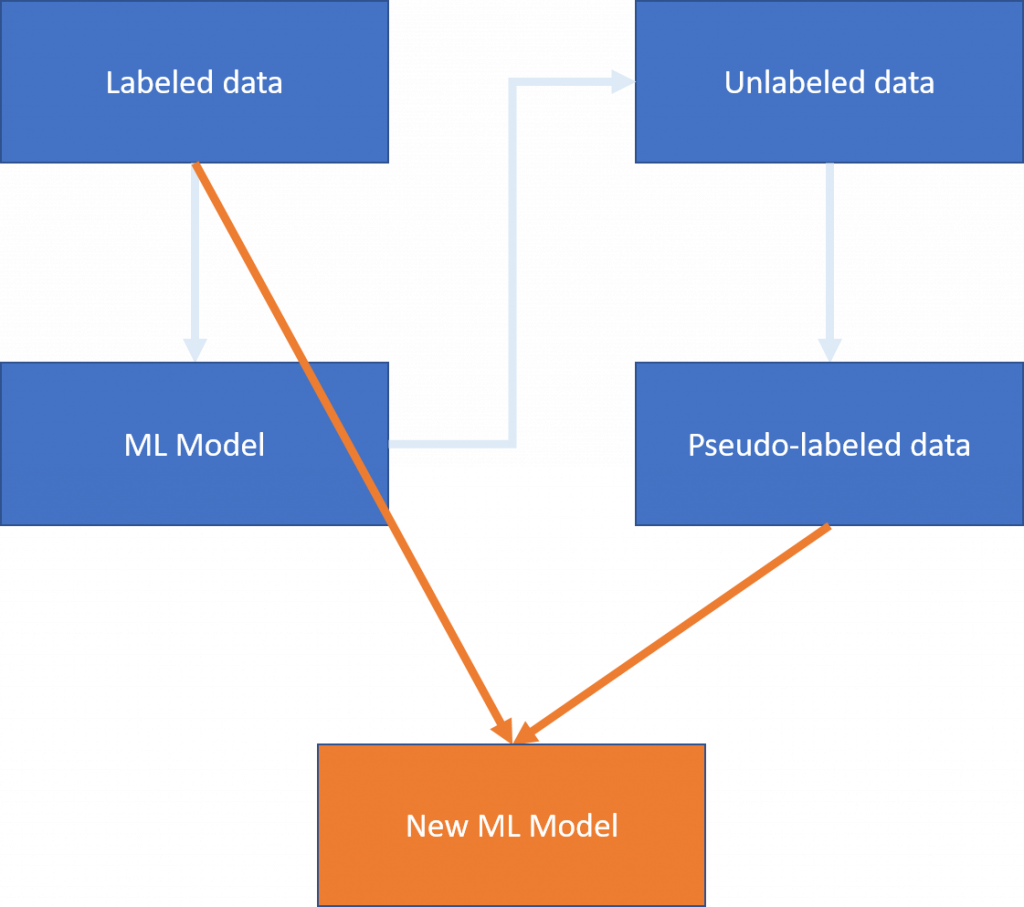
試想你是一個國一新生班級的導師,
今天是開學第一天,你要幫大家分組,但對於學生們完全不熟,
於是你想出一個奇招...
導師:我在這邊選出三位小組長(⊕)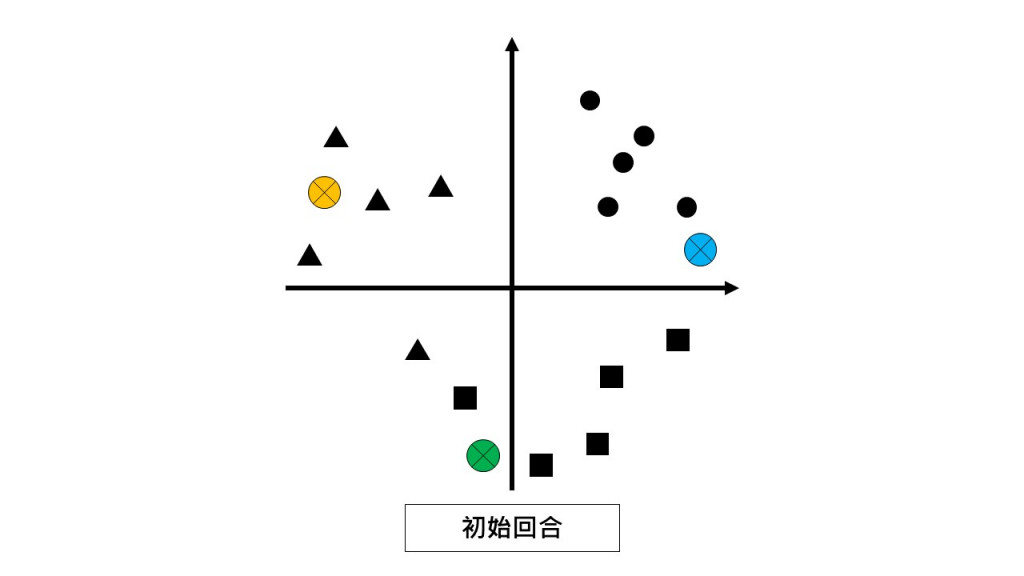
第一回合:請同學們都不要動,根據和你離最近的小組長回報你是哪一組的。(E-step)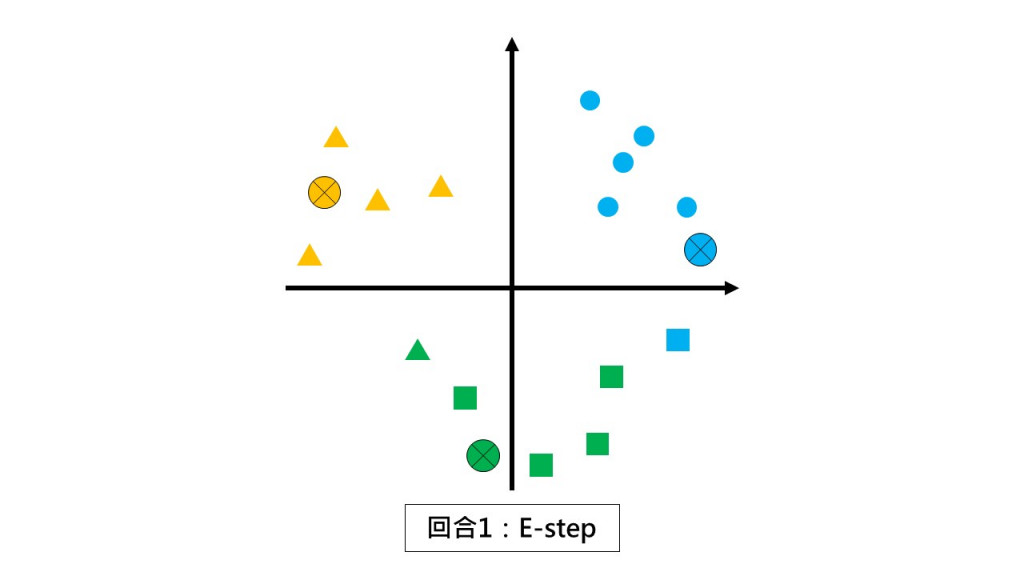
第一回合:請各組以組中心的位置當作新小組長。(M-step)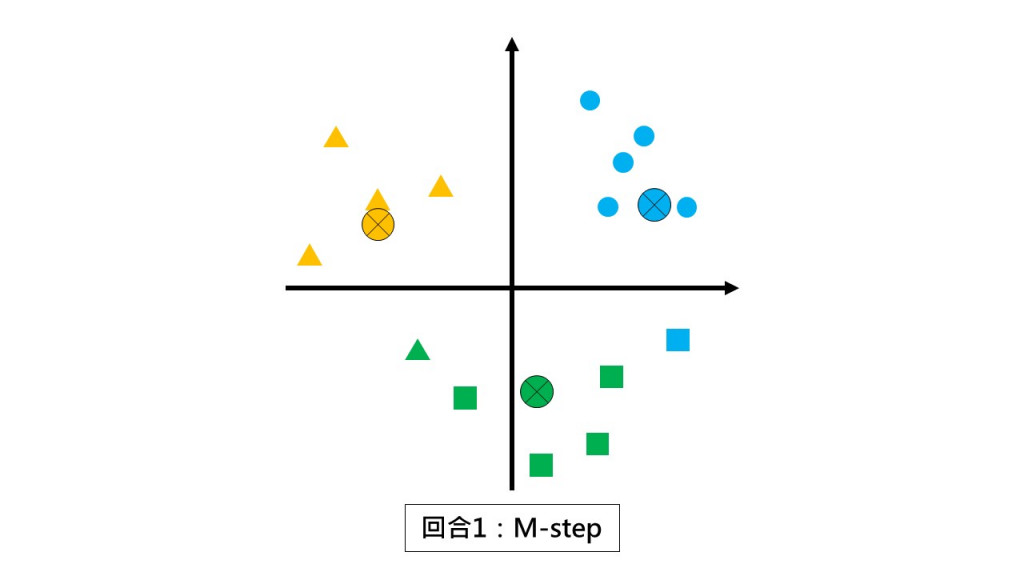
第二回合 E-step:請同學們都不要動,根據和你離最近的小組長回報你是哪一組的。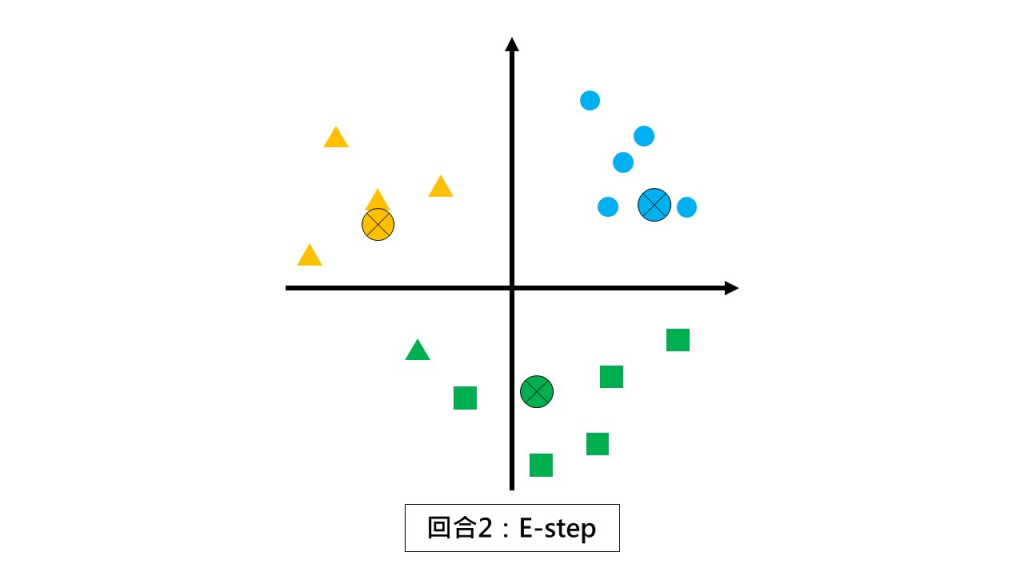
第二回合 M-step:請各組以組中心的位置當作新小組長。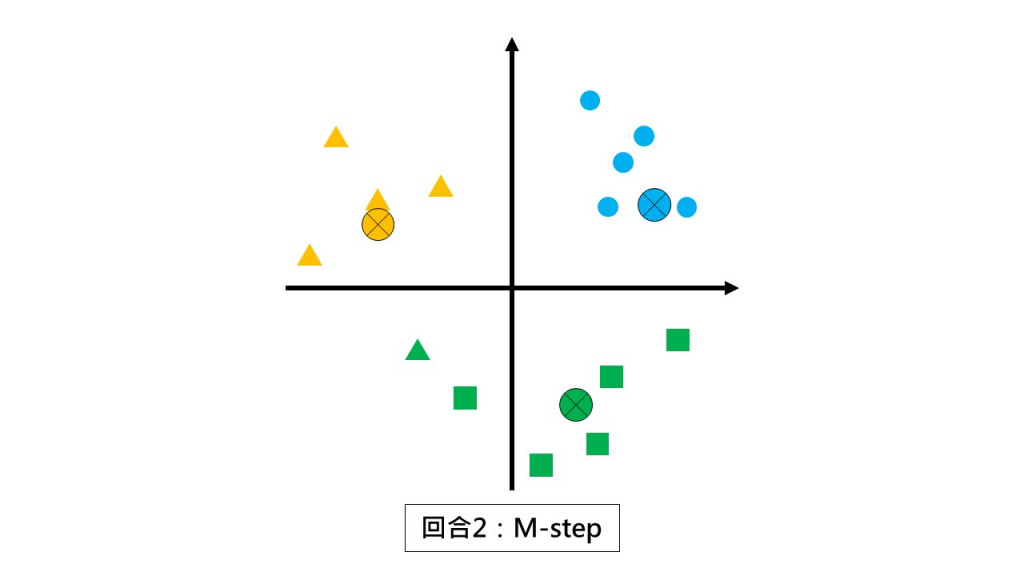
第三回合 E-step:請同學們都不要動,根據和你離最近的小組長回報你是哪一組的。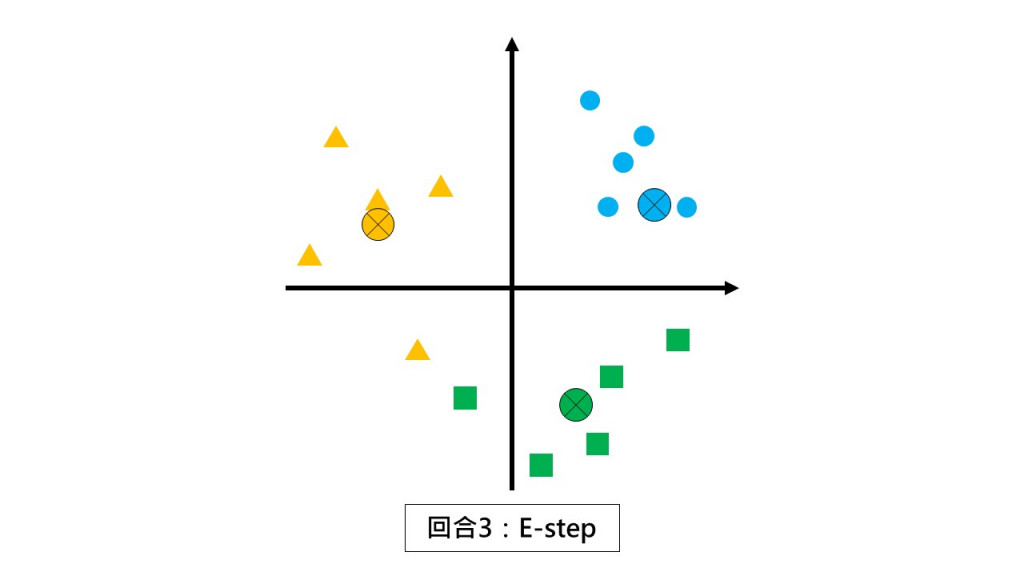
第三回合 M-step:請各組以組中心的位置當作新小組長。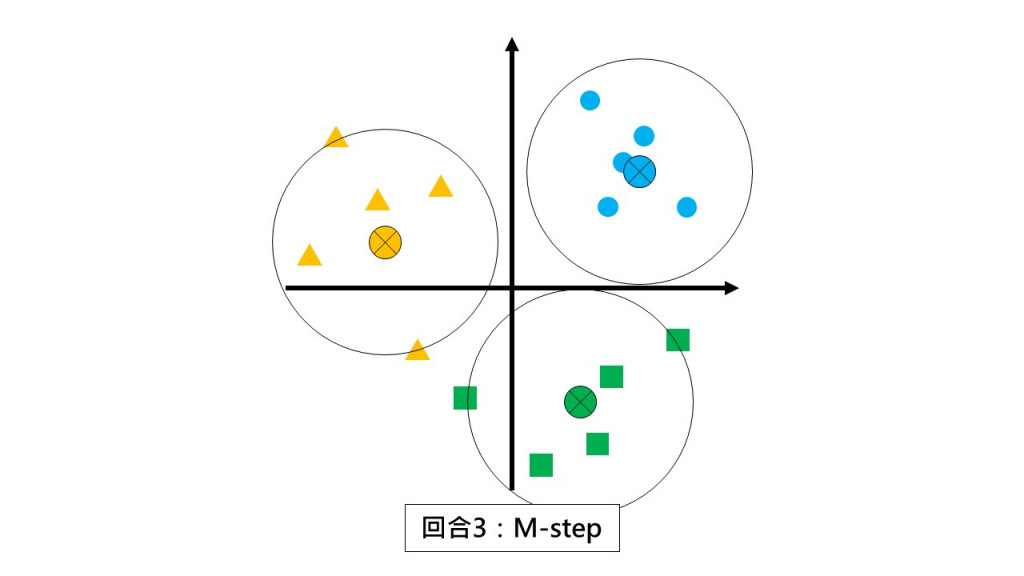
好了,這時候你就會發現:
這時候你就要問了:什麼是 E-step 和 M-step ?
EM全名為Expectation-Maximization,EM演算法又稱最大期望演算法。
E-step為計算期望值,M-step則為最大概似估計,用來更新E-step上的隱藏參數。
在k-means中,這個參數就是平均值(μ)。
演算法數學式: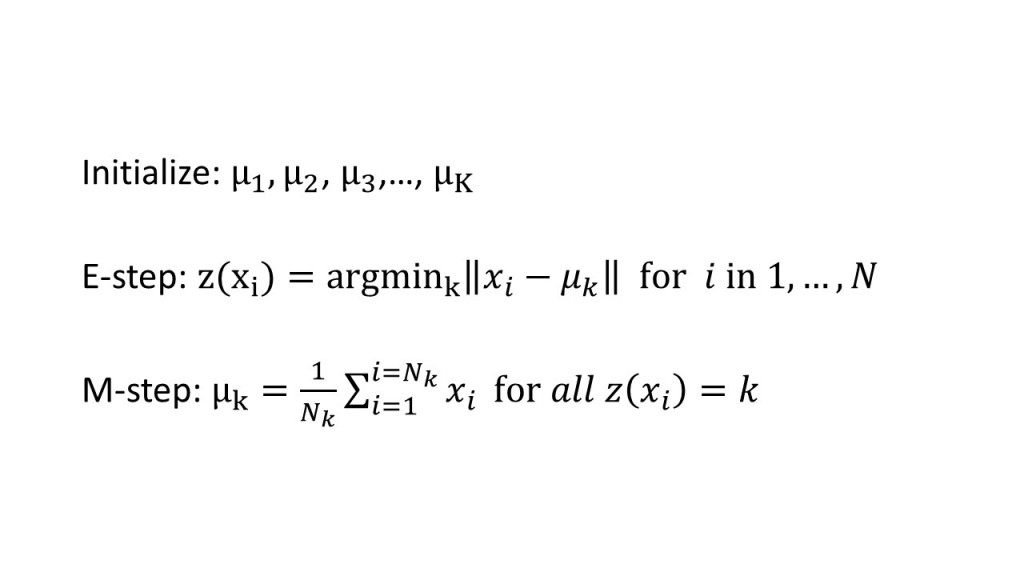
k-means流程如下:
想像我們有一個損失函數,其計算方式為該組的點與組中心的距離平方和。
如何讓這個損失函數最小化呢?那就是用選用x的平均值取代所有x,
而這個步驟其實就是M-step在做的呢!
理論介紹完了,今天也快結束了。
明天讓我們進入k-means實作吧!
